昨天我們進行RAG的介紹、使用RAG的步驟與優劣勢,那麼今天我們將會介紹我們在LangChain使用RAG的詳細步驟,畢竟會需要外部資料源,我們之後會從資料的部分開始進行說明。
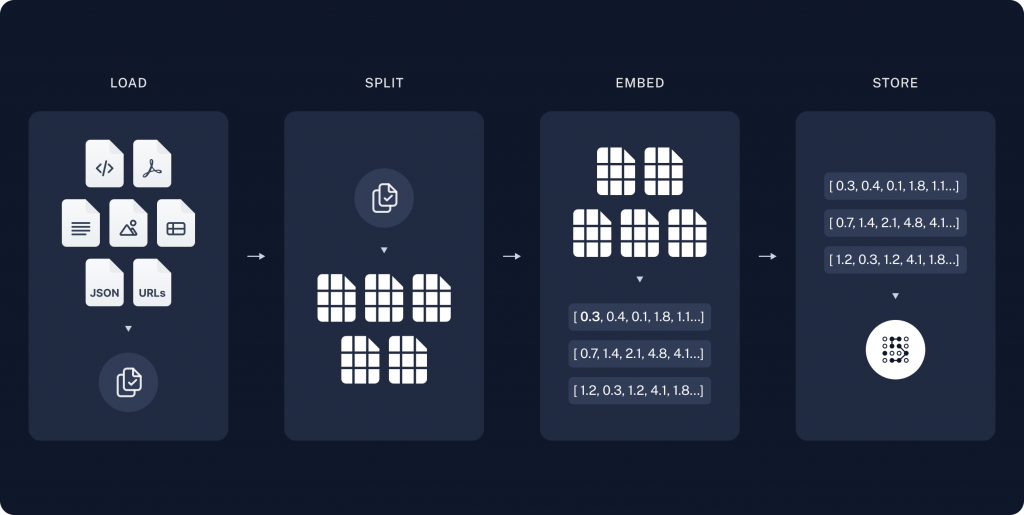
轉成向量後,同樣保持著原本的語意資訊,並且使用者進行查詢後,將使用者查詢轉成向量,可以直接在向量資料庫中進行語意相似度分析,若都是純文字,則進行關鍵字比對,向量更高效之外,也更加精準。
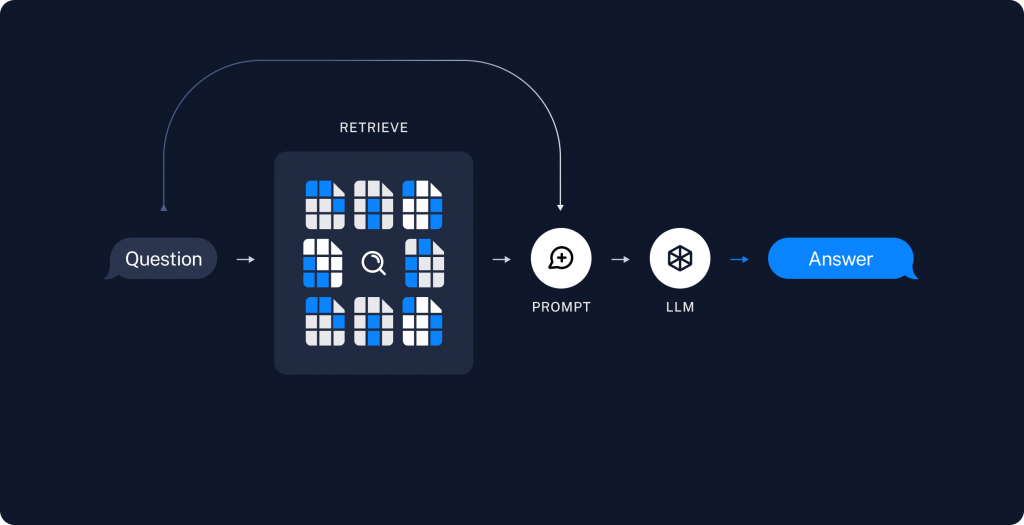
https://python.langchain.com/v0.2/docs/tutorials/rag/
明天我們會先以網頁當作第一個資料源,並且使用Chroma開源的免費向量資料庫,並且進行RAG的示範案例

